
In Part 1, we will discuss how to use Bayesian statistics for data analysis.
When to use Bayesian statistics
Low sample size Bayesian statistics are useful when you have low sample sizes. Most frequentist statistics involve assumptions about the variance of your data. These assumptions are not very good when you are working with low sample sizes, since you simply don’t have much information. Depending on your underlying distribution, a low sample size could be 10 or 1,000 samples.
Inference Bayesian statistics produces probabilities and probability distributions. These are much easier to interpret than p-values, and may have uses for applications such as modeling.
Prior information Bayesian statistics can incorporate all the prior information you have on your data. You can summarize the past literature in your prior distribution, and control and analyze the effect of the weight of this information on your estimates.
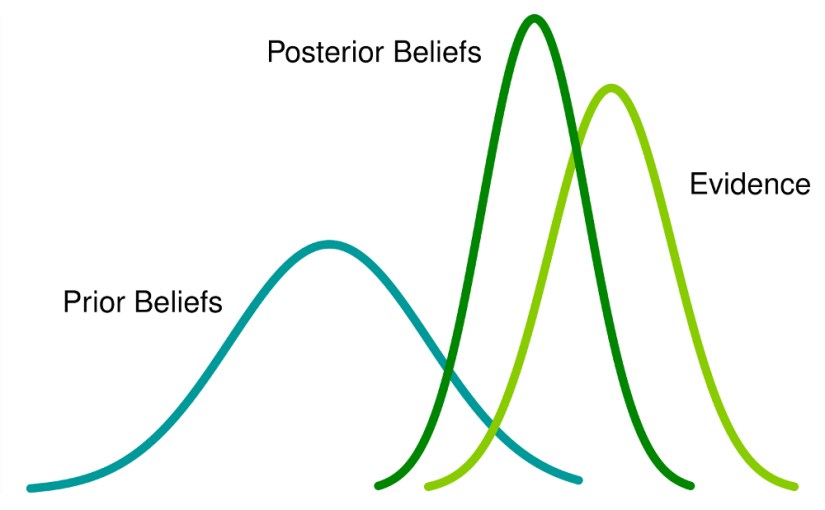
Constructing the Bayesian model
First you need to choose a likelihood that represents your data. The most popular distributions are normal, binomial, and poisson. If your underlying process has some probability, like a coin flip, the binomial is a good choice. Since the binomial is discrete, the beta can be used for continuous data with a simple substitution. If your underlying process is random, like time to event, then poisson is appropriate. For most other types of data, the normal is useful.
Your prior summarizes all the available knowledge on the data you are working with. You will need a prior for each parameter of the likelihood distribution you chose. You can also use priors that are objective, meaning they provide no information on the parameters. You can also use hyperparameters, or parameters that describe the likelihood distribution’s parameters.
Next week I will discuss some useful probability distributions. In Part 2, we will discuss how to use Markov chain monte carlo to estimate parameters.
